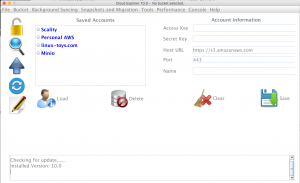
Cloud Explorer is a powerful GUI and CLI Amazon S3 client. In this release there is many code improvements to help users sync their data to a S3 bucket and migrate data between different S3 providers. There is also better support for S3 compatible servers such as Scality S3 Server and Minio.
Syncing, bucket migrations, and snapshots were completely rewritten for optimal performance. Now five sync tasks can run at the same time. Each task will check the file metadata and perform the necessary upload and download operations concurrently instead of a single operation at a time.
The Background sync feature enables users to perform a bidirectional sync on a folder like Dropbox in the GUI or CLI every five minutes. This feature was also rewritten and takes advantage of the improved syncing algorithms discussed earlier. Since it now runs in it’s own thread with a separate configuration file, users can use Cloud Explorer while the sync tasks run in the background.
Path Style access is now enabled for non-aws accounts providing better support for private S3 compatible servers like Scality and Minio. Users will now also be able to connect to these servers by IP address or DNS.
Regions have been removed from the code and configuration file. Cloud Explorer will retrieve the appropriate region from the S3 account resulting in better functionality and easier use. This being said, that means that previous Cloud Explorer configuration files will not work in the new release and the accounts will have to be added again.
The CLI now supports bucket snapshots and migrations with the ability to use environment variables instead of a configuration file. This functionality makes it easier to run in a container such as Docker or Rocket.
I hope that you will enjoy this exciting new release and please provide feedback on the GitHub or directly to me on .